
Duplicate content is content that appears on the Internet in more than one place. That “one place” is defined as a location with a unique website address (URL) – so, if the same content appears at more than one web address, you’ve got duplicate content.
While not technically a penalty, duplicate content can still sometimes impact search engine rankings. When there are multiple pieces of, as Google calls it, “appreciably similar” content in more than one location on the Internet, it can be difficult for search engines to decide which version is more relevant to a given search query.
Why does duplicate content matter?
For search engines
Duplicate content can present three main issues for search engines:
- They don’t know which version(s) to include/exclude from their indices.
- They don’t know whether to direct the link metrics (trust, authority, anchor text, link equity, etc.) to one page, or keep it separated between multiple versions.
- They don’t know which version(s) to rank for query results.
For site owners
When duplicate content is present, site owners can suffer rankings and traffic losses. These losses often stem from two main problems:
- To provide the best search experience, search engines will rarely show multiple versions of the same content, and thus are forced to choose which version is most likely to be the best result. This dilutes the visibility of each of the duplicates.
- Link equity can be further diluted because other sites have to choose between the duplicates as well. instead of all inbound links pointing to one piece of content, they link to multiple pieces, spreading the link equity among the duplicates. Because inbound links are a ranking factor, this can then impact the search visibility of a piece of content.
The net result? A piece of content doesn’t achieve the search visibility it otherwise would.

How do duplicate content issues happen?
In the vast majority of cases, website owners don’t intentionally create duplicate content. But, that doesn’t mean it’s not out there. In fact by some estimates, up to 29% of the web is actually duplicate content!
Let’s take a look at some of the most common ways duplicate content is unintentionally created:
1. URL variations
URL parameters, such as click tracking and some analytics code, can cause duplicate content issues. This can be a problem caused not only by the parameters themselves, but also the order in which those parameters appear in the URL itself.
For example:
- www.widgets.com/blue-widgets?color=blue is a duplicate of www.widgets.com/blue-widgets
- www.widgets.com/blue-widgets?color=blue&cat=3 is a duplicate of www.widgets.com/blue-widgets?cat=3&color=blue
Similarly, session IDs are a common duplicate content creator. This occurs when each user that visits a website is assigned a different session ID that is stored in the URL.

Printer-friendly versions of content can also cause duplicate content issues when multiple versions of the pages get indexed.

One lesson here is that when possible, it’s often beneficial to avoid adding URL parameters or alternate versions of URLs (the information those contain can usually be passed through scripts).
2. HTTP vs. HTTPS or WWW vs. non-WWW pages
If your site has separate versions at “www.site.com” and “site.com” (with and without the “www” prefix), and the same content lives at both versions, you’ve effectively created duplicates of each of those pages. The same applies to sites that maintain versions at both http:// and https://. If both versions of a page are live and visible to search engines, you may run into a duplicate content issue.
3. Scraped or copied content
Content includes not only blog posts or editorial content, but also product information pages. Scrapers republishing your blog content on their own sites may be a more familiar source of duplicate content, but there’s a common problem for e-commerce sites, as well: product information. If many different websites sell the same items, and they all use the manufacturer’s descriptions of those items, identical content winds up in multiple locations across the web.
How to fix duplicate content issues
Fixing duplicate content issues all comes down to the same central idea: specifying which of the duplicates is the “correct” one.
Whenever content on a site can be found at multiple URLs, it should be canonicalized for search engines. Let’s go over the three main ways to do this: Using a 301 redirect to the correct URL, the rel=canonical attribute, or using the parameter handling tool in Google Search Console.
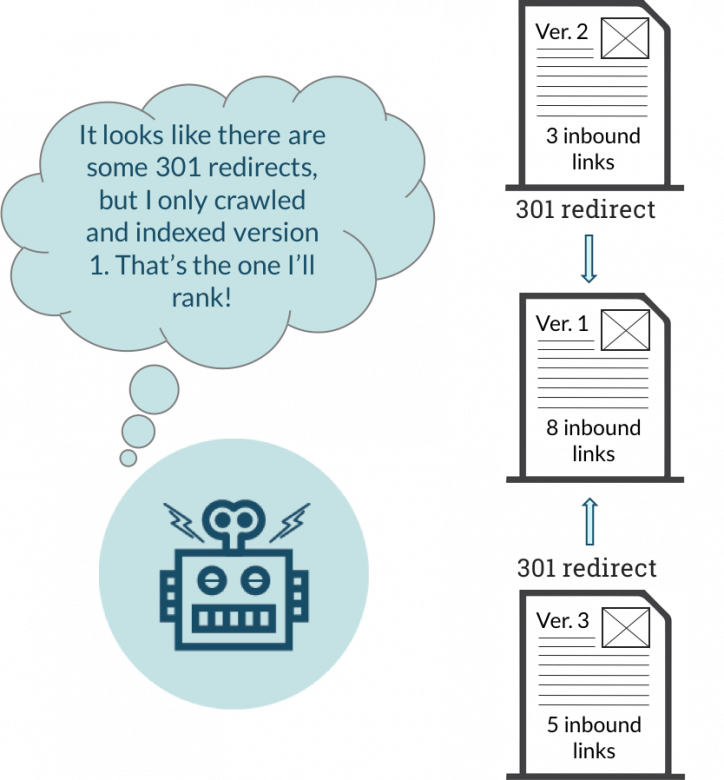
301 redirect
In many cases, the best way to combat duplicate content is to set up a 301 redirect from the “duplicate” page to the original content page.
When multiple pages with the potential to rank well are combined into a single page, they not only stop competing with one another; they also create a stronger relevancy and popularity signal overall. This will positively impact the “correct” page’s ability to rank well.
Rel=”canonical”
Another option for dealing with duplicate content is to use the rel=canonical attribute. This tells search engines that a given page should be treated as though it were a copy of a specified URL, and all of the links, content metrics, and “ranking power” that search engines apply to this page should actually be credited to the specified URL.

The rel=”canonical” attribute is part of the HTML head of a web page and looks like this:
General format:
<head> ...[other code that might be in your document's HTML head]... <link href="URL OF ORIGINAL PAGE" rel="canonical" /> ...[other code that might be in your document's HTML head]... </head>
The rel=canonical attribute should be added to the HTML head of each duplicate version of a page, with the “URL OF ORIGINAL PAGE” portion above replaced by a link to the original (canonical) page. (Make sure you keep the quotation marks.) The attribute passes roughly the same amount of link equity (ranking power) as a 301 redirect, and, because it’s implemented at the page (instead of server) level, often takes less development time to implement.
Below is an example of what a canonical attribute looks like in action:
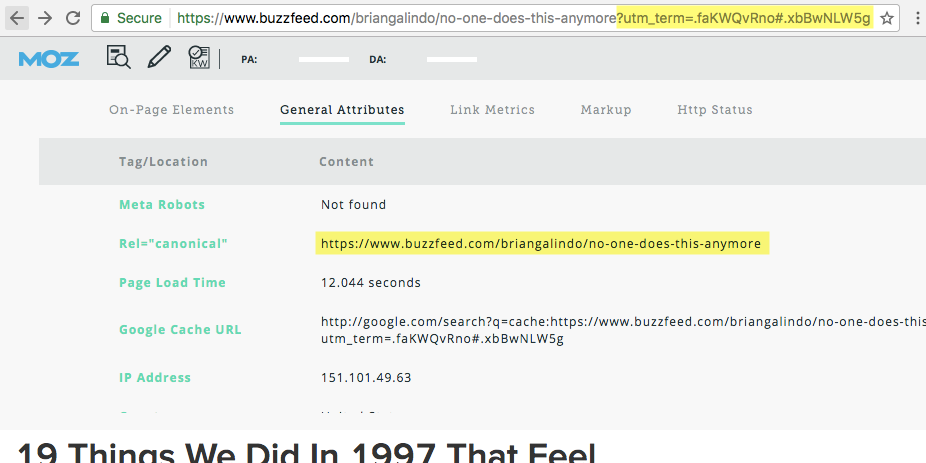
Using MozBar to identify canonical attributes.
Here, we can see BuzzFeed is using the rel=canonical attributes to accommodate their use of URL parameters (in this case, click tracking). Although this page is accessible by two URLs, the rel=canonical attribute ensures that all link equity and content metrics are awarded to the original page (/no-one-does-this-anymore).
Meta Robots Noindex
One meta tag that can be particularly useful in dealing with duplicate content is meta robots, when used with the values “noindex, follow.” Commonly called Meta Noindex,Follow and technically known as content=”noindex,follow” this meta robots tag can be added to the HTML head of each individual page that should be excluded from a search engine’s index.
General format:
<head> ...[other code that might be in your document's HTML head]... <meta name="robots" content="noindex,follow"> ...[other code that might be in your document's HTML head]... </head>
The meta robots tag allows search engines to crawl the links on a page but keeps them from including those links in their indices. It’s important that the duplicate page can still be crawled, even though you’re telling Google not to index it, because Google explicitly cautions against restricting crawl access to duplicate content on your website. (Search engines like to be able to see everything in case you’ve made an error in your code. It allows them to make a [likely automated] “judgment call” in otherwise ambiguous situations.)
Using meta robots is a particularly good solution for duplicate content issues related to pagination.
Preferred domain and parameter handling in Google Search Console
Google Search Console allows you to set the preferred domain of your site (i.e. http://yoursite.com instead of http://www.yoursite.com) and specify whether Googlebot should crawl various URL parameters differently (parameter handling).

Depending on your URL structure and the cause of your duplicate content issues, setting up either your preferred domain or parameter handling (or both!) may provide a solution.
The main drawback to using parameter handling as your primary method for dealing with duplicate content is that the changes you make only work for Google. Any rules put in place using Google Search Console will not affect how Bing or any other search engine’s crawlers interpret your site; you’ll need to use the webmaster tools for other search engines in addition to adjusting the settings in Search Console.
Additional methods for dealing with duplicate content
- Maintain consistency when linking internally throughout a website. For example, if a webmaster determines that the canonical version of a domain is www.example.com/, then all internal links should go to http://www.example.com/example rather than http://example.com/page (notice the absence of www).
- When syndicating content, make sure the syndicating website adds a link back to the original content and not a variation on the URL. (Check out our Whiteboard Friday episode on dealing with duplicate content for more information.)
- To add an extra safeguard against content scrapers stealing SEO credit for your content, it’s wise to add a self-referential rel=canonical link to your existing pages. This is a canonical attribute that points to the URL it’s already on, the point being to thwart the efforts of some scrapers.

- A self-referential rel=canonical link: The URL specified in the rel=canonical tag is the same as the current page URL.
While not all scrapers will port over the full HTML code of their source material, some will. For those that do, the self-referential rel=canonical tag will ensure your site’s version gets credit as the “original” piece of content.
