
Robots.txt is a text file webmasters create to instruct web robots (typically search engine robots) how to crawl pages on their website. The robots.txt file is part of the the robots exclusion protocol (REP), a group of web standards that regulate how robots crawl the web, access and index content, and serve that content up to users. The REP also includes directives like meta robots, as well as page-, subdirectory-, or site-wide instructions for how search engines should treat links (such as “follow” or “nofollow”).
In practice, robots.txt files indicate whether certain user agents (web-crawling software) can or cannot crawl parts of a website. These crawl instructions are specified by “disallowing” or “allowing” the behavior of certain (or all) user agents.
Basic format:
User-agent: [user-agent name] Disallow: [URL string not to be crawled]
Together, these two lines are considered a complete robots.txt file — though one robots file can contain multiple lines of user agents and directives (i.e., disallows, allows, crawl-delays, etc.).
Within a robots.txt file, each set of user-agent directives appear as a discrete set, separated by a line break:

In a robots.txt file with multiple user-agent directives, each disallow or allow rule only applies to the useragent(s) specified in that particular line break-separated set. If the file contains a rule that applies to more than one user-agent, a crawler will only pay attention to (and follow the directives in) the most specific group of instructions.

Msnbot, discobot, and Slurp are all called out specifically, so those user-agents will only pay attention to the directives in their sections of the robots.txt file. All other user-agents will follow the directives in the user-agent: * group.
Example robots.txt:
Here are a few examples of robots.txt in action for a www.example.com site:
Robots.txt file URL: www.example.com/robots.txt
Blocking all web crawlers from all content
User-agent: * Disallow: /
Using this syntax in a robots.txt file would tell all web crawlers not to crawl any pages on www.example.com, including the homepage.
Allowing all web crawlers access to all content
User-agent: * Disallow:
Using this syntax in a robots.txt file tells web crawlers to crawl all pages on www.example.com, including the homepage.
Blocking a specific web crawler from a specific folder
User-agent: Googlebot Disallow: /example-subfolder/
This syntax tells only Google’s crawler (user-agent name Googlebot) not to crawl any pages that contain the URL string www.example.com/example-subfolder/.
Blocking a specific web crawler from a specific web page
User-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
This syntax tells only Bing’s crawler (user-agent name Bing) to avoid crawling the specific page at www.example.com/example-subfolder/blocked-page.
How does robots.txt work?
Search engines have two main jobs:
- Crawling the web to discover content;
- Indexing that content so that it can be served up to searchers who are looking for information.
To crawl sites, search engines follow links to get from one site to another — ultimately, crawling across many billions of links and websites. This crawling behavior is sometimes known as “spidering.”
After arriving at a website but before spidering it, the search crawler will look for a robots.txt file. If it finds one, the crawler will read that file first before continuing through the page. Because the robots.txt file contains information about how the search engine should crawl, the information found there will instruct further crawler action on this particular site. If the robots.txt file does not contain any directives that disallow a user-agent’s activity (or if the site doesn’t have a robots.txt file), it will proceed to crawl other information on the site.
Other quick robots.txt must-knows:
(discussed in more detail below)
- In order to be found, a robots.txt file must be placed in a website’s top-level directory.
- Robots.txt is case sensitive: the file must be named “robots.txt” (not Robots.txt, robots.TXT, or otherwise).
- Some user agents (robots) may choose to ignore your robots.txt file. This is especially common with more nefarious crawlers like malware robots or email address scrapers.
- The /robots.txt file is a publicly available: just add /robots.txt to the end of any root domain to see that website’s directives (if that site has a robots.txt file!). This means that anyone can see what pages you do or don’t want to be crawled, so don’t use them to hide private user information.
- Each subdomain on a root domain uses separate robots.txt files. This means that both blog.example.com and example.com should have their own robots.txt files (at blog.example.com/robots.txt and example.com/robots.txt).
- It’s generally a best practice to indicate the location of any sitemaps associated with this domain at the bottom of the robots.txt file. Here’s an example:
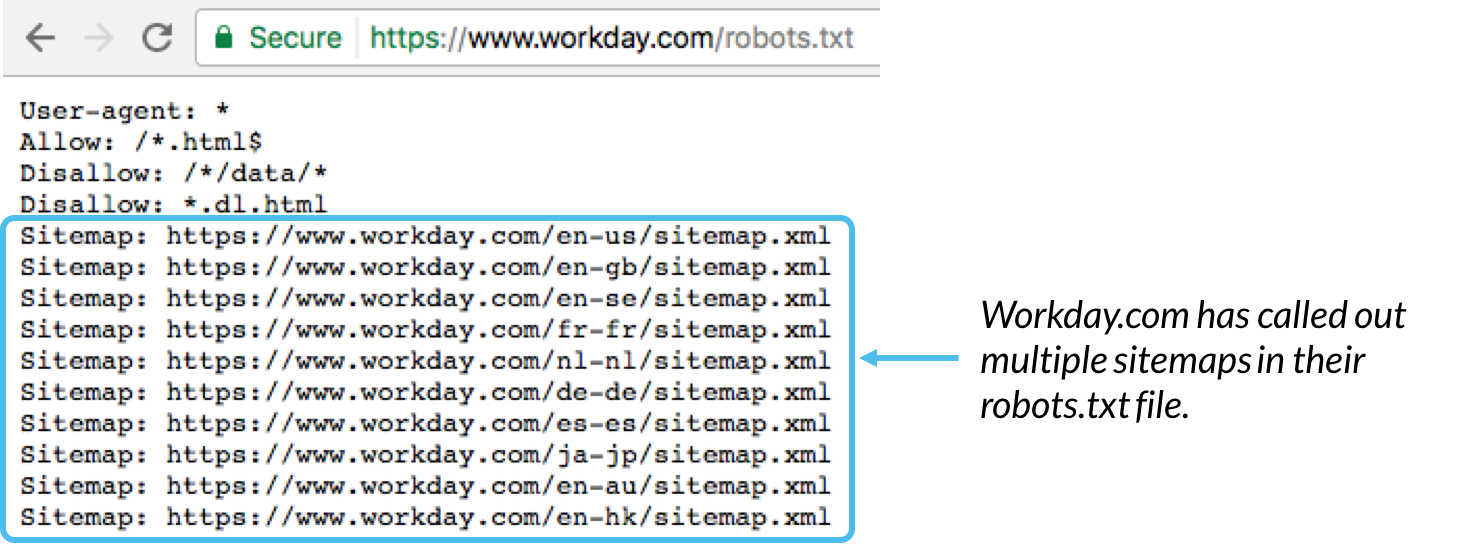
Technical robots.txt syntax
Robots.txt syntax can be thought of as the “language” of robots.txt files. There are five common terms you’re likely come across in a robots file. They include:
- User-agent: The specific web crawler to which you’re giving crawl instructions (usually a search engine). A list of most user agents can be found here.
- Disallow: The command used to tell a user-agent not to crawl particular URL. Only one “Disallow:” line is allowed for each URL.
- Allow (Only applicable for Googlebot): The command to tell Googlebot it can access a page or subfolder even though its parent page or subfolder may be disallowed.
- Crawl-delay: How many milliseconds a crawler should wait before loading and crawling page content. Note that Googlebot does not acknowledge this command, but crawl rate can be set in Google Search Console.
- Sitemap: Used to call out the location of any XML sitemap(s) associated with this URL. Note this command is only supported by Google, Ask, Bing, and Yahoo.
Pattern-matching
When it comes to the actual URLs to block or allow, robots.txt files can get fairly complex as they allow the use of pattern-matching to cover a range of possible URL options. Google and Bing both honor two regular expressionsthat can be used to identify pages or subfolders that an SEO wants excluded. These two characters are the asterisk (*) and the dollar sign ($).
- * is a wildcard that represents any sequence of characters
- $ matches the end of the URL
Google offers a great list of possible pattern-matching syntax and examples here.
Where does robots.txt go on a site?
Whenever they come to a site, search engines and other web-crawling robots (like Facebook’s crawler, Facebot) know to look for a robots.txt file. But, they’ll only look for that file in one specific place: the main directory (typically your root domain or homepage). If a user agent visits www.example.com/robots.txt and does not find a robots file there, it will assume the site does not have one and proceed with crawling everything on the page (and maybe even on the entire site). Even if the robots.txt page did exist at, say, example.com/index/robots.txt or www.example.com/homepage/robots.txt, it would not be discovered by user agents and thus the site would be treated as if it had no robots file at all.
In order to ensure your robots.txt file is found, always include it in your main directory or root domain.
Why do you need robots.txt?
Robots.txt files control crawler access to certain areas of your site. While this can be very dangerous if you accidentally disallow Googlebot from crawling your entire site (!!), there are some situations in which a robots.txt file can be very handy.
Some common use cases include:
- Preventing duplicate content from appearing in SERPs (note that meta robots is often a better choice for this)
- Keeping entire sections of a website private (for instance, your engineering team’s staging site)
- Keeping internal search results pages from showing up on a public SERP
- Specifying the location of sitemap(s)
- Preventing search engines from indexing certain files on your website (images, PDFs, etc.)
- Specifying a crawl delay in order to prevent your servers from being overloaded when crawlers load multiple pieces of content at once
If there are no areas on your site to which you want to control user-agent access, you may not need a robots.txt file at all.
Checking if you have a robots.txt file
Not sure if you have a robots.txt file? Simply type in your root domain, then add /robots.txt to the end of the URL. For instance, Moz’s robots file is located at moz.com/robots.txt.
If no .txt page appears, you do not currently have a (live) robots.txt page.
How to create a robots.txt file
If you found you didn’t have a robots.txt file or want to alter yours, creating one is a simple process. This articlefrom Google walks through the robots.txt file creation process, and this tool allows you to test whether your file is set up correctly.
Looking for some practice creating robots files? This blog post walks through some interactive examples.
SEO best practices
- Make sure you’re not blocking any content or sections of your website you want crawled.
- Links on pages blocked by robots.txt will not be followed. This means 1.) Unless they’re also linked from other search engine-accessible pages (i.e. pages not blocked via robots.txt, meta robots, or otherwise), the linked resources will not be crawled and may not be indexed. 2.) No link equity can be passed from the blocked page to the link destination. If you have pages to which you want equity to be passed, use a different blocking mechanism other than robots.txt.
- Do not use robots.txt to prevent sensitive data (like private user information) from appearing in SERP results. Because other pages may link directly to the page containing private information (thus bypassing the robots.txt directives on your root domain or homepage), it may still get indexed. If you want to block your page from search results, use a different method like password protection or the noindex meta directive.
- Some search engines have multiple user-agents. For instance, Google uses Googlebot for organic search and Googlebot-Image for image search. Most user agents from the same search engine follow the same rules so there’s no need to specify directives for each of a search engine’s multiple crawlers, but having the ability to do so does allow you to fine-tune how your site content is crawled.
- A search engine will cache the robots.txt contents, but usually updates the cached contents at least once a day. If you change the file and want to update it more quickly than is occurring, you can submit your robots.txt url to Google.
Robots.txt vs meta robots vs x-robots
So many robots! What’s the difference between these three types of robot instructions? First off, robots.txt is an actual text file, whereas meta and x-robots are meta directives. Beyond what they actually are, the three all serve different functions. Robots.txt dictates site or directory-wide crawl behavior, whereas meta and x-robots can dictate indexation behavior at the individual page (or page element) level.
