
Robots meta directives (sometimes called “meta tags”) are pieces of code that provide crawlers instructions for how to crawl or index web page content. Whereas robots.txt file directives give bots suggestions for how to crawl a website’s pages, robots meta directives provide more firm instructions on how to crawl and index a page’s content.
There are two types of robots meta directives: those that are part of the HTML page (like the meta robotstag) and those that the web server sends as HTTP headers (such as x-robots-tag). The same parameters (i.e., the crawling or indexing instructions a meta tag provides, such as “noindex” and “nofollow” in the example above) can be used with both meta robots and the x-robots-tag; what differs is how those parameters are communicated to crawlers.
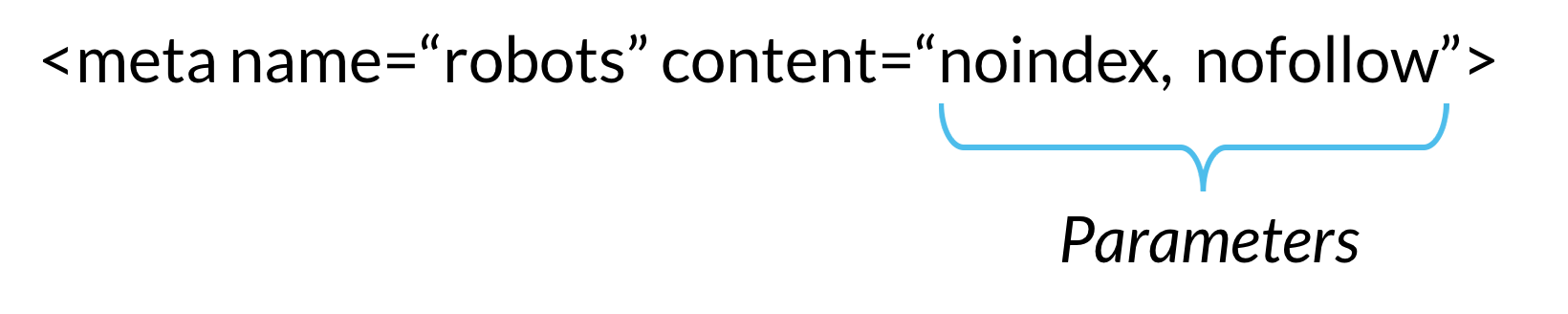
Meta directives give crawlers instructions about how to crawl and index information they find on a specific webpage. If these directives are discovered by bots, their parameters serve as strong suggestions for crawler indexation behavior. But as with robots.txt files, crawlers don’t have to follow your meta directives, so it’s a safe bet that some malicious web robots will ignore your directives.
Below are the parameters that search engine crawlers understand and follow when they’re used in robots meta directives. The parameters are not case-sensitive, but do note that it is possible some search engines may only follow a subset of these parameters or may treat some directives slightly differently.
Indexation-controlling parameters:
- Noindex: Tells a search engine not to index a page.
- Index: Tells a search engine to index a page. Note that you don’t need to add this meta tag; it’s the default.
- Follow: Even if the page isn’t indexed, the crawler should follow all the links on a page and pass equity to the linked pages.
- Nofollow: Tells a crawler not to follow any links on a page or pass along any link equity.
- Noimageindex: Tells a crawler not to index any images on a page.
- None: Equivalent to using both the noindex and nofollow tags simultaneously.
- Noarchive: Search engines should not show a cached link to this page on a SERP.
- Nocache: Same as noarchive, but only used by Internet Explorer and Firefox.
- Nosnippet: Tells a search engine not to show a snippet of this page (i.e. meta description) of this page on a SERP.
- Noodyp/noydir [OBSOLETE]: Prevents search engines from using a page’s DMOZ description as the SERP snippet for this page. However, DMOZ was retired in early 2017, making this tag obsolete.
- Unavailable_after: Search engines should no longer index this page after a particular date.
Types of robots meta directives
There are two main types of robots meta directives: the meta robots tag and the x-robots-tag. Any parameter that can be used in a meta robots tag can also be specified in an x–robots–tag.
We’ll talk about both the meta robots and x-robots tag directives below.
Meta robots tag
The meta robots tag, commonly known as “meta robots” or colloquially as a “robots tag,” is part of a web page’s HTML code and appears as code elements within a web page’s <head> section:

Code sample:
<meta name=“robots” content=“[PARAMETER]”>
While the general <meta name=“robots” content=“[PARAMETER]”> tag is standard, you can also provide directives to specific crawlers by replacing the “robots” with the name of a specific user-agent. For example, to target a directive specifically to Googlebot, you’d use the following code:
<meta name=“googlebot” content=“[DIRECTIVE]”>
Want to use more than one directive on a page? As long as they’re targeted to the same “robot” (user-agent), multiple directives can be included in one meta directive – just separate them by commas. Here’s an example:
<meta name=“robots” content=“noimageindex,” “nofollow,” “nosnippet”>
This tag would tell robots not to index any of the images on a page, follow any of the links, or show a snippet of the page when it appears on a SERP.
If you’re using different meta robots tag directives for different search user-agents, you’ll need to use separate tags for each bot.
X-robots-tag
While the meta robots tag allows you to control indexing behavior at the page level, the x-robots-tag can be included as part of the HTTP header to control indexing of a page as a whole, as well as very specific elements of a page.
While you can use the x-robots-tag to execute all of the same indexation directives as meta robots, the x-robots-tag directive offers significantly more flexibility and functionality that the meta robots tag does not. Specifically, the x-robots permits the use of regular expressions, executing crawl directives on non-HTML files, and applying parameters at a global level.
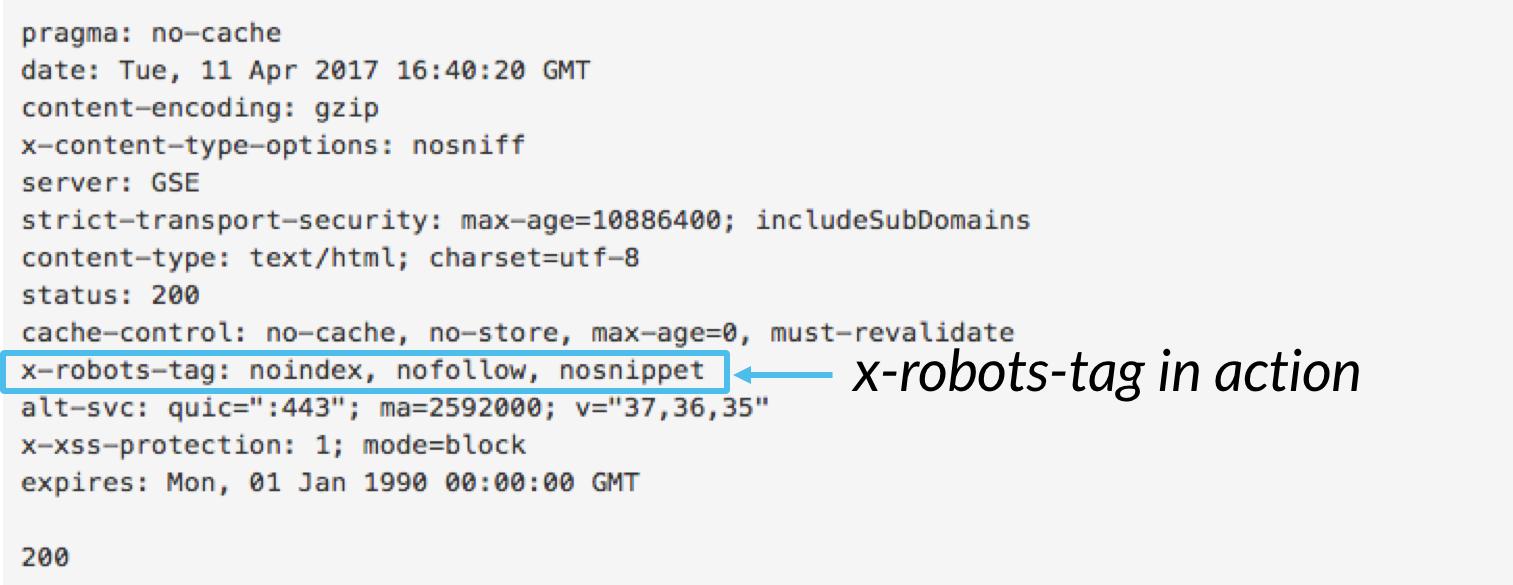
To use the x-robots-tag, you’ll need to have access to either your website’s header .php, .htaccess, or server access file. From there, add your specific server configuration’s x-robots-tag markup, including any parameters. This article provides some great examples of what x-robots-tag markup looks like if you’re using any of these three configurations.
Here are a few use cases for why you might employ the x-robots-tag:
- Controlling the indexation of content not written in HTML (like flash or video)
- Blocking indexation of a particular element of a page (like an image or video), but not of the entire page itself
- Controlling indexation if you don’t have access to a page’s HTML (specifically, to the <head> section) or if your site uses a global header that cannot be changed
- Adding rules to whether or not a page should be indexed (ex. If a user has commented over 20 times, index their profile page)
SEO best practices with robots meta directives
- All meta directives (robots or otherwise) are discovered when a URL is crawled. This means that if a robots.txt file disallows the URL from crawling, any meta directive on a page (either in the HTML or the HTTP header) will not be seen and will, effectively, be ignored.
- In most cases, using a meta robots tag with parameters “noindex, follow” should be employed as a way to to restrict crawling or indexation instead of using robots.txt file disallows.
- It is important to note that malicious crawlers are likely to completely ignore meta directives and as such, this protocol does not make a good security mechanism. If you have private information that you don’t want to make publicly searchable, choose a more secure approach, such as password protection, to keep visitors from viewing confidential pages.
- You do not need to use both meta robots and the x-robots-tag on the same page – doing so would be redundant.
